Инструменты пользователя
Это старая версия документа!
Samba Cluster
Введение
Предоставление файловых сервисов пользователям является типичной задачей и трудно найти офисную сеть в которой такие сервисы не работают. Наиболее распространенные протоколы - NFS(сетевая файловая система) и CIFS(windows shares и их аналог в *nix Samba), второй встречается намного чаще. В некоторых же бизнес-процессах файловый сервис занимает ключевую роль, например как в моей сети. У меня имеется хранилище объемом больше сотни терабайт и клиенты, которые исчисляются сотнями, работающие с этим хранилищем по протоколу CIFS. Каждый клиент подключен к сети по 1Гбит линку. Глядя на эти исходные данные, становится понятно, что CIFS-сервер должен быть достаточно производительным и иметь скоростной канал связи, например 10Гбит, но и этого со временем становится не достаточно, рано или поздно наступает момент, когда в высоту расти уже не получается(т.е. увеличивать производительность одного сервера), приходит время расти в ширину(т.е. увеличивать кол-во серверов), чем собственно в этой статье и займемся.
Итак, исходные данные: имеем сотни терабайт данных и сотни высокоскоростных клиентов. Задача: построить отказоустойчивый высокоскоростной файловый кластер под управлением Linux и Samba. Кластер должен выполнять задачу подмены вышедших из строя узлов, а также распределение нагрузки по всем узлам кластера.
Для решения этой задачи будет использоваться свободный аналог Red Hat 7 - Centos 7, хотя я и являюсь сторонником GNU/Debian, но в данной задачей, когда речь идет о дорогом брендовом оборудовании, чтобы не поиметь проблем с совместимостью, лучше использовать рекомендованные и поддерживаемые вендором ОС.
Основные компоненты схематично указаны на рисунке ниже.
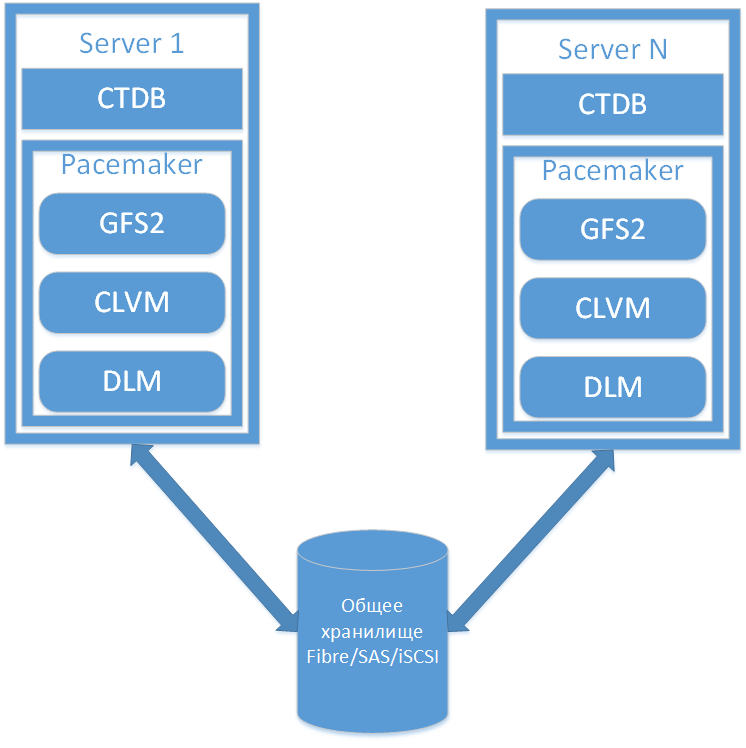
Как видно из схемы, два(или более) сервера имеют доступ к общему хранилищу данных, чтобы корректно с ним работать, кто-то должен отвечать за контроль доступа к хранилищу и за блокировки, т.к. никак не связанные между собой сервера работают с общим ресурсом. Именно этой задачей, т.е. межпроцессной синхронизацией, и будет заниматься DLM(distrubuted lock manager). Далее нам понадобится кластерная файловая система, например GFS, в этой статье используется GFS2, она не работает напрямую с блочными устройствами, для нее нужен LVM(logical volume manager), но в нашем случае нужна кластерная его реализация - CLVM, но хорошая новость в том, что CLVM отличается от LVM по большому счету только наличием сервиса clvmd и небольшими настройками конфигурационного файла. Ну и наконец поверх DLM и CLVM находится сама кластерная ФС - GFS2. Всеми этими компонентами управляет Pacemaker, он обеспечивает запуск нужных служб, на нужных узлах и в нужном порядке, а также отслеживает их состояние, т.е. выполняет мониторинг.
Итак, кластерная ФС, которая доступна на всех узлах у нас уже есть, осталось запустить файловую службу Samba, в этой статье используется 4-ая ветка. Но просто так это сделать нельзя, если мы не хотим получить неожиданные результат, например в виде испорченных данных. Т.е. Samba также нуждается в механизме управления блокировками, более того у всех узлов должна быть общая БД. В Samba используется TDB(trivial data base), в нашей конфигурации потребуется ее кластерная реализация - CTDB, которая кроме всего прочего умеет еще самостоятельно управлять службами winbind и smbd, т.е. запускать и останавливать их на нужных узлах и самое главное - CTDB берет на себя ф-ию по управлению IP-адресами узлов. Что это значит? Допустим у нас есть два узла с адресами 1.1.1.1 и 2.2.2.2 и один из узлов стал недоступен, об этом сразу станед известно CTDB и эта служба перенесет оба IP-адреса на оставшийся работающий узел, а также разошлет всем клиентам отказавшего узла уведомления о том, что TCP-соединение необходимо переустановить.
<note> Во всех документациях говорится, что по фен шую функционал по управлению службами smbd, winbind, а также IP-адресами должен выполнятся службой управления кластера Pacemaker. Т.е. CTDB должен быть сконфигурирован таким образом, что он не будет управлять ни службами, ни IP-адресами кластера. Он должен быть сконфигурирован как отдельный ресурс кластера, службы smbd и winbind также ресурсы кластера, которые запускаются после CTDB и IP-адреса аналогично, присваиваются после запуска smbd. Все это должно быть сконфигурировано таким образом с точки зрения красоты архитектуры, чтобы узлами кластера управляла одна система - Pacemaker, а не две Pacemaker и CTDB. В Pacemaker есть даже RA(resource agent) ocf:heartbeat:CTDB, который управляет службой CTDB, есть RA ocf:heartbeat:IPaddr2 для управления IP-адресами, есть даже RA ocf:heartbeat:portblock для отсылки уведомлений клиентам о том, что узел более недоступен(Tickle ACK), НО до сих пор нет RA для управления smbd и winbind, поэтому этими службами все же должен управлять CTDB, якобы это временно и вот-вот должны появится RA для Samba, но это было написано в 2010г и на текущий момент(2014г) ничего не изменилось. Поэтому лично я не вижу смысла отдавать управление адресами и Samba Pacemaker'у, потому что, во-первых, это несколько усложняет конфигурацию кластера, во-вторых, с этой задачей неплохо справляется сам CTDB и у него хорошо проработанные утилиты для мониторига и отслеживания состояния кластера. </note>
Подготовка системы
Имеем два хоста с установленной ОС Linux Centos 7. Выполняем обновление системы.
# yum update
Отключаем SELinux, редактируем /etc/sysconfig/selinux:
SELINUX=disabled
Выключаем фаервол
# systemctl stop firewalld # systemctl disable firewalld
либо добавляем правила разрешающие узлам кластера взаимодействовать
# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availability
Настраиваем сеть, на каждом хосте по два сетевых интерфейса eth0 и eth1, первый используется для внутрикластерного взаимодействия и имеет сеть 192.168.232.0/24, а второй для обслуживания клиентов, сеть 10.0.0.0/24. Если в кластере всего два узла, то рекомендуется подключить интерфейсы eth0 напрямую друг к другу кросс-кабелем, для того, чтобы избежать лишней точки отказа - свитча. Итак, конфигурируем сеть, у первого узла будет адрес 192.168.232.10, у второго 192.168.232.20. Пример конфига /etc/sysconfig/network-scripts/ifcfg-eth0:
DEVICE=eth0 ONBOOT=yes BOOTPROTO=static TYPE=Ethernet IPADDR=192.168.232.10 PREFIX=24
Настраиваем имена хостов, допустим samba_node1 и samba_node2, соответственно на каждом узле отдельно, /etc/hostname:
samba_node1
Теперь надо настроить надежное разрешение имен на обоих узлах, а еще лучше, чтобы не зависеть еще от одного сервиса(DNS) и избавиться от дополнительной точки отказа, пропишем соответствие адреса и имени на каждом узле в /etc/hosts:
192.168.232.10 samba_node1 192.168.232.20 samba_node2
Перезагружаем оба узла
# reboot
Проверяем на обоих узлах
[samba_node1 ~]# ping -c 1 samba_node2 PING samba_node2 (192.168.232.20) 56(84) bytes of data. 64 bytes from samba_node2 (192.168.232.20): icmp_seq=1 ttl=64 time=0.297 ms [samba_node2 ~]# ping -c 1 samba_node1 PING samba_node1 (192.168.232.10) 56(84) bytes of data. 64 bytes from samba_node1 (192.168.232.10): icmp_seq=1 ttl=64 time=0.323 ms
Устанавливаем необходимое ПО
# yum groupinstall "High Availability" # yum install samba samba-client
Первоначальная настройка кластера
На всех узлах устанавливаем пароль на пользователя hacluster
# passwd hacluster
Включаем сервис pcsd на всех узлах
# systemctl start pcsd.service # systemctl enable pcsd.service
Авторизуем узлы в кластере(команда выполняется на любом узле), авторизуемся с пользователем hacluster и паролем, который установили ранее
# pcs cluster auth samba_node1 samba_node2 Username: hacluster Password: samba_node1: Authorized samba_node2: Authorized
Создаем кластер(команда выполняется на любом узле)
# pcs cluster setup --start --name samba_cluster samba_node1 samba_node2 Shutting down pacemaker/corosync services... Redirecting to /bin/systemctl stop pacemaker.service Redirecting to /bin/systemctl stop corosync.service Killing any remaining services... Removing all cluster configuration files... samba_node1: Succeeded samba_node1: Starting Cluster... samba_node2: Succeeded samba_node2: Starting Cluster...
Здесь samba_node1 и samba_node2 - имена узлов кластера, а samba_cluster - имя создаваемого кластера. В результате выполнения этой команды будет сгенерирован файл /etc/corosync/corosync.conf примерно такого содержания:
totem {
version: 2
secauth: off
cluster_name: samba_cluster
transport: udpu
}
nodelist {
node {
ring0_addr: samba_node1
nodeid: 1
}
node {
ring0_addr: samba_node2
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_syslog: yes
}
Включаем автозагрузку кластера(команда выполняется на любом узле)
# pcs cluster enable --all
Выключаем механизм stonith(команда выполняется на любом узле)
# pcs property set stonith-enabled=false
<note important> Механизм stonith отвечает за физическое отключение узла кластера, это может понадобится, когда связь с этим узлом потеряна и его состояние не известно, поэтому во избежании порчи данных узел с неизвестным состоянием изолируется(fence), т.е. физически выключается. Обычно для этих задач используют специальные адаптеры питания с функцией управления по сети. В боевых условиях отключать механизм stonith крайне не рекомендуется, но т.к. мы настраивает тестовую конфигурацию, мы так поступим. </note>