Вводные данные по DRBD
Distributed Replicated Block Device - это сетевой RAID-1 на блочном уровне для linux систем. Он должен состоять из двух узлов, хотя возможны конфигурации, когда строятся цеопчки из DRBD-устройств. Поддеживается несколько режимов работы: Master/Slave и Master/Master. В первом случае запись возможна только на Master узле, во втором на любом узле. DRBD низкоуровневое устройство, т.е. оно оперирует с данными на блочном уровне, а не на уровне файловой системы. Таким образом, поверх DRBD-устройства может функционировать любая поддерживамая файловая система или виртуальная машина, например XEN, в общем с ним можно обращаться как с обычным жестким диском, создавать разделы, LVM-тома и т.д.
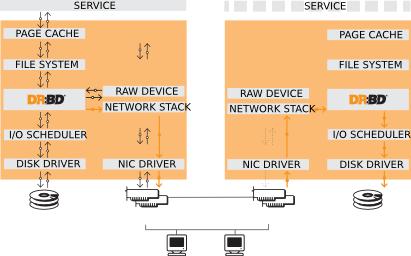
Существует три протокола синхронизации DRBD-устройств. Синхронный «C», когда запись считается завершенной только если оба узла сообщили об успешном выполнении операции. Асинхронный «A», когда запись выполнилась на локальном узле, а на удаленный узел данные только отправлены. И промежуточный вариант «B», когда запись выполнилась на локальном узле, а удаленный узел подтвердил получение данных(но не запись их!).
Работает DRBD на уровне ядра (как подгружаемый модуль). В качестве транспортного уровня используется протокол TCP 4 или 6 версии без шифрования и аутентификации. Наличие на пути канала связи маршрутизаторов не рекомендуется из-за больших задержек и низкой производительности. Также поддерживается некоторый экзотический протокол SuperSockets с низкими задержками, но он поддерживается только очень редким спецефическим оборудованием, в общем по факту этого протокола нет и о нем в большинстве случаев можно не думать  Целостность передаваемых данных по каналам связи может контролироваться с помощью контрольных сумм, например md5.
Целостность передаваемых данных по каналам связи может контролироваться с помощью контрольных сумм, например md5.
Основная единица, с которой оперирует DRBD - ресурс. Рерсурсом в данном контексте называется одно DRBD-устройство, у которого есть имя и номер(а также ряд других настроек, все это задается в конфигурационном файле). Имя ресурса используется при выполнении административных операций с помощью утилит администрирования, а номер(может начинаться с 0) - это порядковый номер DRBD-устройства /dev/drbdX.
Оба узла в нормальном режиме всегда имеют актуальную локальную копию ресурсов, т.к. при записе на мастере, данные тут же отображаются на слейве(в случае протокола С), но возможны ситуации, когда слейв был недоступен, а в этот момент выполнялась запись на мастер, тогда происходит рассинхронизация ресурсов. В таком случае ресурс на слейве получает статус Outdated. После восстановления связи, будет выполнена синхнронизация между мастером и слейвом.
Кроме автоматической синхронизации возможна автоматическая(с помощью cron) или ручная верификация данных. Т.е. на одном из узлов, считающимся эталонным, выполняется поблоковое чтение и рассчет контрольной суммы блока, которая затем передается на другой узел и там выполняется аналогичная операция, затем контрольные суммы сравниваются. Если они отличаются, то блок помечается как рассинхронизированный и в логи пишется сообщение. Затем может быть выполнена синхронизация. Для верификации не требуется отключение устройств, т.е. она может выполняться в онлайне. Верификация не сильно грузит сеть, т.к. передаются только контрольные суммы, а не сами не сами блоки данных. Но при этом процессор и дисковая подсистема испытывают ощутимую нагрузку.
У каждого ресурса есть метаданные, которые могут храниться на самом DRBD-устройстве, либо на другом блочном устройстве. Использование внешнего устройства дает следующие преимущества: возможность создать DRBD-устройстве поверх уже существующего устройства с данными, без их потери; возможность добиться некоторого увеличения производительности операций записи, если устройство для метаданных на физическом уровне является отдельным. К недостаткам такого подхода можно отнести сложности с администрированием и восстановлением в случае сбоев.
У всех современных дисков и raid-контроллеров есть встроенный кеш, таким образом, при выполнении операций записи, они сообщают операционной системе о том, что операция завершилась, когда все данные влезли в кеш, но на самом деле еще могли не записаться на энергонезависимые носители. Это может привести к порче как самих данных, так и метаданных DRBD-устройств в случае сбоев электропитания. Чтобы предотвратить подобные ситуации, рекомендуется отключать встроенный кеш дисков и контроллеров(disk flushes). Но если raid-контроллер имеет на борту батарейку, которая позволит сохранить данные в кеше в случае непредвиденного отключения электропитания, disk flushes можно отключить, это может ощутимо повысить производительность операций записи.
Существует две стратегии обработки проблем с блочными устройствами поверх которых работает DRBD:
- Passing on I/O errors - если устройство сообщаем о проблемах с вводом/выводом, то эта ошибка передается дальше, на верхний уровень, например файловой системе, что в свою очередь может привести к перемонитированию ее в ремим только для чтения. Такой подход не обеспечивает отказоустойчивости и не рекомендуется к применению.
- Masking I/O errors - если устройство сообщаем о проблемах с вводом/выводом, то в зависимости от конфигурации, DRBD может выполнить detach для проблемного устройства и перевести его в режим diskless. Однако сама ошибка ввода/вывода никак не сообщается вверх по уровню, проблемный блок будет прочитан по сети на втором узле. Не смотря на то, что производительность при этом пострадается, система продложит функционировать.
Бывает несколько вариантов рассинхронизации данных: inconsistent и outdated. Первый случай может быть к примеру когда еще не выполнена первичная синхронизация данных, второй, когда случилась рассинхронизация по причине потери связи между узлами.
После создания, инициализации и синхронизации ресурса, один из узлов(или оба) становится мастером. Если перезагрузить слейв, то он после запуска подключится к мастеру и синхронизирует все изменения. Но если перезагрузить мастер, то он после загрузки станит в режим слейв. Т.е. оба узла будут в режиме слейв и нужно будет вручную повысить один из узлов до уровня мастер. Но как правило DRBD используется с системами кластеризации, такими как pacemaker, в этом случае все эти действия выполняет менеджер кластера.
В случае использования в качестве транспорта TCP, крайне желательно, даже настоятельно рекомендуется, соединять узлы между собой прямым соединением, т.е. без промежуточного свитча(кросс-кабелем). Это нужно для того, чтобы исключить дополнительную точку отказа на транспортном уровне, т.к. подобные сбои приносят большие проблемы(об этом ниже). Часто на практике используют резервирование каналов(linux bonding в режиме master/backup).
В случае потери канала связи, по которому происходит синхронизация и при этом используется система управления кластером, либо по другим причинам, например человекческий фактор, может сложиться такая ситуация, когда оба узла переходят в режим мастер, но при этом не синхронизируются друг с другом, потому что потеряна связь, в результате чего у каждого узла получается своя модифицированная версия данных, которую уже невозможно синхронизировать, это явление называется split brain. После восстановления связи между узлами, узел, который обнаружил split brain переходит в режим StandAlone. DRBD имеет возможность автоматически уведомлять администратора, в случае возникновения такой ситуации.
Решить эту проблему можно либо вручную, либо в автоматическом режиме. В ручном режиме администратор сам выбирает из двух узлов жертву, т.е. узел, на котором изменения будут потеряны и он станет слейвом, после чего синхронизирует изменения с мастера. Как уже упоминалось, существует автоматический режим, который отключен по умолчанию. Существует три алгоритма автоматического решения проблемы split brain:
- Discarding modifications made on the “younger” primary - в этом режиме, после восстановления связи между узлами, изменения будут отвергнуты на узле, который стал мастером последним, т.е. который был мастер меньшее кол-во времени.
- Discarding modifications made on the “older” primary - все наоборот, после восстановления связи, в качестве жертвы будет выбран узел, который стал матером первым.
- Graceful recovery from split brain if one host has had no intermediate changes - это более «интуитивный» режим, если среди узлов есть такой, на котором не было сделано никаких изменения на DRBD-устройстве, то он выбирается в качестве жертвы и на него выполняется синхронизация. Однако, такой сценарий крайне маловероятен, т.к. при монтировании файловой системы с устройства, даже в режиме только для чтения, устройство уже будет иметь изменения.
Выбор режима восстановления split brain зависит от конкретных приложений, которые работают поверх DRBD. Для некоторых может быть приемлемо потерять некотоые изменения, а для некоторых нет, например финансовые базы данных, в этом случае должен использоваться только ручной режим или вообще не использоваться DRBD.