Инструменты пользователя
Это старая версия документа!
Вводные данные по DRBD
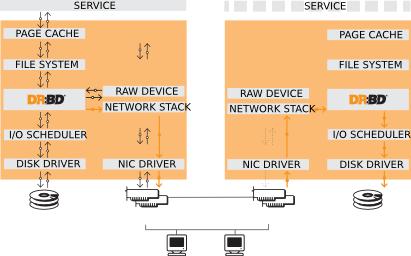
Distributed Replicated Block Device - это сетевой RAID-1 на блочном уровне для linux систем. Он должен состоять из двух узлов, хотя возможны конфигурации, когда строятся цеопчки из DRBD-устройств. Поддеживается несколько режимов работы: Master/Slave и Master/Master. В первом случае запись возможна только на Master узле, во втором на любом узле. DRBD низкоуровневое устройство, т.е. оно оперирует с данными на блочном уровне, а не на уровне файловой системы. Таким образом, поверх DRBD-устройства может функционировать любая поддерживамая файловая система или виртуальная машина, например XEN, в общем с ним можно обращаться как с обычным жестким диском, создавать разделы, LVM-тома и т.д.
Существует три протокола синхронизации DRBD-устройств. Синхронный «C», когда запись считается завершенной только если оба узла сообщили об успешном выполнении операции. Асинхронный «A», когда запись выполнилась на локальном узле, а на удаленный узел данные только отправлены. И промежуточный вариант «B», когда запись выполнилась на локальном узле, а удаленный узел подтвердил получение данных(но не запись их!).
Работает DRBD на уровне ядра (как подгружаемый модуль). В качестве транспортного уровня используется протокол TCP 4 или 6 версии без шифрования и аутентификации. Также поддерживается некоторый экзотический протокол SuperSockets с низкими задержками, но он поддерживается только очень редким спецефическим оборудованием, в общем по факту этого протокола нет и о нем в большинстве случаев можно не думать ![]() Целостность передаваемых данных по каналам связи может контролироваться с помощью контрольных сумм, например md5.
Целостность передаваемых данных по каналам связи может контролироваться с помощью контрольных сумм, например md5.
Основная единица, с которой оперирует DRBD - ресурс. Серсурсом в данном контексте называется одно DRBD-устройство, у которого есть имя и номер(а также ряд других настроек, все это задается в конфигурационном файле). Имя ресурса используется при выполнении административных операций с помощью утилит администрирования, а номер(может начинаться с 0) - это порядковый номер DRBD-устройства /dev/drbdX.
Оба узла в нормальном режиме всегда имеют актуальную локальную копию ресурсов, т.к. при записе на мастере, данные тут же отображаются на слейве(в случае протокола С), но возможны ситуации, когда слейв был недоступен, а в этот момент выполнялась запись на мастер, тогда происходит рассинхронизация ресурсов. В таком случае ресурс на слейве получает статус Outdated. После восстановления связи, будет выполнена синхнронизация между мастером и слейвом.
Кроме автоматической синхронизации возможна автоматическая(с помощью cron) или ручная верификация данных. Т.е. на одном из узлов, считающимся эталонным, выполняется поблоковое чтение и рассчет контрольной суммы блока, которая затем передается на другой узел и там выполняется аналогичная операция, затем контрольные суммы сравниваются. Если они отличаются, то блок помечается как рассинхронизированный и в логи пишется сообщение. Затем может быть выполнена синхронизация. Для верификации не требуется отключение устройств, т.е. она может выполняться в онлайне. Верификация не сильно грузит сеть, т.к. передаются только контрольные суммы, а не сами не сами блоки данных. Но при этом процессор и дисковая подсистема испытывают ощутимую нагрузку.
У каждого ресурса есть метаданные, которые могут храниться на самом DRBD-устройстве, либо на другом блочном устройстве. Использование внешнего устройства дает следующие преимущества: возможность создать DRBD-устройстве поверх уже существующего устройства с данными, без их потери; возможность добиться некоторого увеличения производительности операций записи, если устройство для метаданных на физическом уровне является отдельным. К недостаткам такого подхода можно отнести сложности с администрированием и восстановлением в случае сбоев.
У всех современных дисков и raid-контроллеров есть встроенный кеш, таким образом, при выполнении операций записи, они сообщают операционной системе о том, что операция завершилась, когда все данные влезли в кеш, но на самом деле еще могли не записаться на энергонезависимые носители. Это может привести к порче как самих данных, так и метаданных DRBD-устройств в случае сбоев электропитания. Чтобы предотвратить подобные ситуации, рекомендуется отключать встроенный кеш дисков и контроллеров(disk flushes). Но если raid-контроллер имеет на борту батарейку, которая позволит сохранить данные в кеше в случае непредвиденного отключения электропитания, disk flushes можно отключить, это может ощутимо повысить производительность операций записи.
Существует две стратегии обработки проблем с блочными устройствами поверх которых работает DRBD:
- Passing on I/O errors - если устройство сообщаем о проблемах с вводом/выводом, то эта ошибка передается дальше, на верхний уровень, например файловой системе, что в свою очередь может привести к перемонитированию ее в ремим только для чтения. Такой подход не обеспечивает отказоустойчивости и не рекомендуется к применению.
- Masking I/O errors - если устройство сообщаем о проблемах с вводом/выводом, то в зависимости от конфигурации, DRBD может выполнить detach для проблемного устройства и перевести его в режим diskless. Однако сама ошибка ввода/вывода никак не сообщается вверх по уровню, проблемный блок будет прочитан по сети на втором узле. Не смотря на то, что производительность при этом пострадается, система продложит функционировать.