Pacemaker, теория
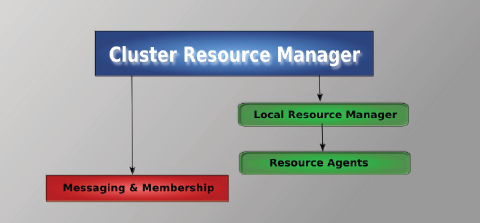
Pacemaker - менеджер ресурсов кластера(Cluster Resource Manager). Его главная задача - достижение максимальной доступности управляемых им ресурсов и защита их от сбоев как на уровне самих ресурсов, так и на уровне целых узлов кластера. Архитектура pacemaker состоит из трех уровней:
- Кластеронезависимый уровень - на этом уровне располагаются сами ресурсы и их скрипты, которыми они управляются и локальный демон, который скрывает от других уровней различия в стандартах, использованных в скриптах (на рисунке зеленый).
- Менеджер ресурсов(Pacemaker), который предстовляет из себя «мозг». Он регирует на события происходящие в кластере: отказ или присоединение узлов, ресурсов, переход узлов в сервисный режим и другие административные действия. Pacemaker исходя из сложившейся ситуации делает рассчет наиболее оптимального состояния кластера и дает команды на выполнения действий для достижения этого состояния(остановка/перенос ресурсов или узлов). На рисунке обозначен синим.
- Информационный уровень - на этом уровне осуществляется сетевое взаимодействие узлов, т.е. передача сервисных команд(запуск/остановка ресурсов, узлов и т.д.), обмен информацией о полноте состава кластера(quorum)и т.д. На рисунке обозначен красным. Как правило на этом уровне работает Corosync/OpenAIS.
Сам pacemaker состоит из четырех ключевых компонентов:
- CIB(Cluster Information Base)
- CRMd(Cluster Resource Management daemon)
- PEngine (PE or Policy Engine)
- STONITHd
CIB - это база данных в формате XML, которая содержит в себе конфигурацию кластера и состояние всех ресурсов кластера. Эта база автоматически реплицируется на весь кластер и ее можно редактировать с любого узла. Она используется PEngine для вычисления идеального состояния кластера и действий, которые приведут к этому состоянию. Этот список действий затем передается DC(Designated Co-ordinator). DC - это главный CRMd, выбранный путем голосования. Если он вдруг становитс недоступен, быстро выбирается другой. Как только DC получил инструкции(список действий) от PEngine, он начинает их распространять в нужном порядке по всему кластеру. На своем узле инструкции сразу попадают к LRMd(Local Resource Manager daemon), на удаленных узлах через информационный уровень(Corosync) они передаются CRMd, который в свою очередь передает их своим локальным LRMd. LRMd через RA(Resource Agent) выполняет все необходимые действия с ресурсом. Узлы, после выполнения полученных инструкций, возвращают результат обратно DC, тот в свою очередь, основываясь на ожидаемых и реально полученных результатах, либо выполняет следующие инструкции, которые ждали завершения предыдущих, либо останавливает выполнение инструкций, если предыдущие не были выполнены корректно. В этом случае DC снова обращается к PEngine за рассчетом новой конфигурации кластера и получением новых инструкций на основне ранее полученных результатов.
Ресурс с точки зрения pacemaker - это все, что можно заскриптовать. Т.е. любой сервис или программа, которая может управляться через скрипты, начиная с простых сервисов типа apache, ip-адрес, и т.д., заканчивая сложными, которые могут работать в разных режимах(primary/secondary, master/slave), например DRBD. RA - это и есть скрипт, который выполняет запуск/останоку ресурса и может возвращать состояние ресурса, т.е. запущен/остановлен и т.д. Кластеризованные ресурсы никогда не должны управляться вручную, т.е. запускаться/останавливаться, а только через административный интерфейс управления кластером. Также они не должны автоматически запускаться при старте системы, т.е. CRMd сам запускает и останавливает ресурсы, когда и где это надо. Существует несколько стандартов RA скриптов, но самый продвинутый и популярный OCF(Open Cluster Framework)
Иногда бывает необходимо физически выключить(обесточить) узел для предотвращения порчи разделяемых данных, либо для завершения каких-либо процедур восстановления. Для этого у pacemaker есть STONITHd. STONITH - это абривиатура от Shoot-The-Other-Node-In-The-Head. Проще говоря, это механизм, который позволяет кластеру выключать/включать/перезагружать узлы физически, если это необходимо, например узел не отвечает, тогда его ресурсы передаются другим узлам, а сам он отключается или если какой-либо ресурс дал сбой и не может быть перезапущен, тогда выполняются те же действия. Обычно это реализуется через сетевые «пилоты» с удаленным управлением или через специальные платы управления сервером. В pacemaker устройства STONITH конфигурируются как ресурсы и также хранятся в CIB.
Pacemaker не делает никаких предположений о вашем окружении, это позволяет поддерживать практически любые отказоустойчивые конфигурации, включая Активный/Активный, Активный/Пассивный, N+1, N+M, N-to-1 и N-to-N.
Ресурсы бывают трех типов:
- Primitive - самый простой тип ресурса, например apache или ip-адрес.
- Clone - ресурс, который может выполняться на нескольких узлах, т.е. чтобы не создавать несоклько однотипных примитивов на разных узлах, используют клоны. Бывает трех подвидов: Anonymous, Globally Unique, Stateful. Anonymous - самый простой, это копии ресурсов с одинаковой функциональностью, они полностью идентичны на всех узлах, поэтому на каждом узле может выполняться не более одного такого клона. Globally Unique - клоны такого типа имеют разную сущность на узлах. Копия запущенная на одном узле не может быть идентична копии запущенной на другом узле. Даже две копии запущенные на одном узле не будут идентичны. Stateful - это специальный тип клона, описан ниже.
- Multi-state - специальный тип Clone-ресурса(его расширение). У этих ресурсов каждый экземпляр ресурса(сущность) может быть только в двух состояниях: Master и Slave. Кол-во сущностей, которое может функционировать в режиме Master конфигурируется(параметр master-max), по-умолчанию 1. У ресурсов такого типа есть два действия: demote и promote, т.е. повышение и понижение. Вначале, после запуска ресурса, все сущности находятся в состоянии Slave и только потом выполняется promote для одной(или нескольких) из сущностей. С помощью дополнителных параметров можно указывать предпочтительную ноду для роли Master.
Таким образом у ресурса может быть три состояния: Started, Slave или Master(последние два только у Multi-state). С помощью правил(rules) можно настроить поведение ресурсов. Например у ресурса есть такой параметр как липкость(stickness), этот параметр указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например после сбоя узла его ресурсы переходят на другие узлы, а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, это поведение как раз и описывается параметром липкость. Т.е. насколько желательно или не желательно(а может не приемлемо), чтобы ресурс вернулся на восстановленный узел. Нежежелательно или неприемлемо это может быть тогда, когда переход ресурса на другой узел влечет за собой некоторый простой в работае ресурса. Липкость ресурса можно воспринимать как «стоимость» простоя ресурса(во время перемещения), чем выше стоимость, тем больше ресурс будет стараться оставаться там, где он есть. По-умолчанию липкость всех ресурсов нулевая, если другое не задано явно. Соответственно pacemaker сам расоплогает ресурсы на узлах «оптимально» с его точки зрения, но это не всегда может быть оптимально с точки зрения администратора. Липкость ресурса можно задать глобально, т.е. дефолтное значение для всех ресурсов или индивидуально. С помощью правил можно задавать разную липкость ресурса в зависимости от времени суток и дня недели, таким образом можно обеспечить переход ресурса на исходный узел в нерабочее время. Еще один вариант использование правил - перемещение ресурсов по узлам в зависимости от времени.
Ресурсы типа примитив(только их) можно объединять в группы(Group). Группа - это набор ресурсов, которые должны выполняться на одном узле и запускаться в указанном порядке(останавливаться в обратном). У группы тоже есть липкость, она равняется сумме липкостей всех активных ресурсов группы. Группой можно управлять как обычным ресурсом, т.е. запускать, останавливать и т.д.
Некоторые ресурсы, например виртуальные машины XEN, могут мигрировать(migrate) на другой узел без потери их состояния, т.е. без остановки работы. Не все ресурсы могут выполнять миграцию, необходимые условия таковы: ресурс должет быть активен и работоспособен на исходном узле и все необходимые условия для запуска ресурса должны быть выполнены на целевом узле. Также RA ресурса должен реализовывать два дополнительных действия: migrate_to и migrate_from. Есть еще другие ограничения: ресурс не должен быть клоном, агент ресурса должен соответствовать стандарту OCF, ресурс не должен прямо или косвенно зависеть от других ресурсов(примитивов или групп), ресурс должен иметь установленный атрибут allow-migrate(по-умолчанию это не так).
Ресурсы имеют множество атрибутов, наиболее интересные из них:
- priority - приоритет ресурса, учитывается, если узел исчерпал лимит по кол-ву активных ресурсов, по дефолту 0.
- resource-stickiness - липкость ресурса, описывалось выше.
- migration-threshold - сколько отказов должно произойти, чтобы ресурс считал ноду непригодной и мигрировал на другую, по дефолту 0, т.е. отключено.
- failure-timeout - кол-во секунд, по истечении которого можно считать, что отказа не происходило, т.е. потенциально разрешаем ресурсу вернуться на тот узел, на котором он отказал и был перемещен.
- multiple-active - что делать с ресурсом, если он оказался запущен более чем на одном узле. Block - установить опцию unmanaged, т.е. деактивировть, stop_only - остановить на всех узлах или stop_start - остановить на всех узлах и запустить только на одном (дефолтное значение).
По-умолчанию кластер не обеспечивает работоспособность ресурсов, т.е. не следит после запуска, жив ли ресурс. Чтобы это происходило, нужно добавлять операцию monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции - интервал с каким делать проверку.
Иногда нужно, чтобы некоторый набор ресурсов выполнялся на одном узле, но не все эти ресурсы являются примитивами, поэтому их нельзя сгруппировать. В этом случае используется colocation - это принуждение к размещению ресурсов на одном узле или наоборот на разных узлах. У colocation есть параметр score, который указывает на то, насколько желательно разместить данный набор ресурсов на одном узле или на разных узлах, соответственно положительное и отрицательное значение(цифра). Но есть специальные значения данного параметра - отрицательная бесконечность и положительная беспонечность(-INFINITY и INFINITY или -inf и inf). При использовании данных ключевых слов, указывается, что ресурсы ОБЯЗАНЫ или НЕ ОБЯЗАНЫ выполнятся на одном узле и никак иначе. При использовании colocation нужно помнить, что порядок указания ресурсов имеет значение, т.к. чтобы знать куда разместить ресурс Б, вначале надо узнать где находится ресурс А. Т.е. вначале запускает ресурс А, исходя из его предпочтений, затем на том же узле размещается ресурс Б. При использовании INFINITY есть некоторые особенности: например указано, что ресурс А и Б обязаны выполняться на узле1 вместе. Но ресурс Б по каким-либо другим ограничениям или принуждениям не может быть запущен на узле1, тогда оба ресурса не будут запущены.
Также может понадобится запускать/останавливать ресурсы в строго заданном порядке, например apache обслуживает сайты, расположенные на файловой системе, соответственно, чтобы apache начал работать, вначале нужно примонтировать файловую систему, а уже потом запускать его. Тут нам поможет ordering - определение зависимости ресурсов друг от друга и определение порядка их запуска(останавливаются они в обратном порядке). Если один из зависимых ресурсов останавливается - останавливаются все. Зависимые ресурсы не обязательно должны выполняться на одном узле.
Ну и наконец location - насколько мы хотим или не хотим, чтобы какой-либо ресурс выполнялся на каком-либо узле. Также, положительное значение - желательно выполнение на данном узле, отрицательное - соответственно не желательно выполнять ресурс на данном узле. Аналогично с INFINITY и -INFINITY, т.е. ресурс должен или не должен выполнятся на указанном узле. Если два узла имеют одинаковый приоритет для ресурса, то кластер сам выберет где запускать ресурс. Есть два подхода определения на каких узлах будут выполнятся какие ресурсы:
- opt-out - создавать все ресурсы с дефолтным расположением на любой доступной ноде, а затем фильтровать не желательные ноды параметром location.
- opt-in - т.е. ресурсы по дефолту не могут выполняться ни на каких узлах, а потом разрешать нужные узлы.
При расчете приоритетов, кластер руководствуется следующими формулами:
- Any value + INFINITY = INFINITY
- Any value - INFINITY = -INFINITY
- INFINITY - INFINITY = -INFINITY
У кластера есть такое понятие как quorum, насколько кластер является правомочным, т.е. может корректно функционировать. Кластер считает себя правочным при наличии более 50% живых узлов(если быть точным, вычисляется по формуле: кол-во_живых_узлов * 2 > всего_узлов, если уравнение истинно, то считается, что кластер имеет quorum). Если кластер не имеет кворума, то по-умлчанию поведение таково: кластер считает себя развалившимся и прекращает функционирование, т.е. останавливает все связанные с кластером ресурсы. Такое поведение не совсем желаемо в некоторых конфигурациях, например кластер состоящий из двух узлов, в этом случае при выходе из строя одного из двух узлов, весь кластер перестает функционировать, в чем тогда смысл кластера?  В таких конфигурация меняют поведение кластера по-умолчанию, указывая, что подобные ситуации(потеря кворума) нужно игнорировать, делается это с помощью опции no-quorum-policy=ignore.
В таких конфигурация меняют поведение кластера по-умолчанию, указывая, что подобные ситуации(потеря кворума) нужно игнорировать, делается это с помощью опции no-quorum-policy=ignore.
Полезные команды
Тут список некоторых полезных команд администрирования кластера.
- crm resource migrate resource1 node1 - миграция ресурса resource1 на узел node1
- crm resource unmigrate resource1 - отмена миграции и возврат ресурса на исходный узел
- crm resource move resource1 node2 - принудительно переместить ресурс resource1 на node2
- crm resource stop resource1 - остановка ресурса resource1
- crm resource start resource1 - соответственно запуск
- crm node standby node1 - перевод узла в сервисный режим, т.е. все ресурсы с него будут перенесены на другие узлы и с ним можно выполнять любые сервисные задачи, в т.ч. выключать.
- crm node online node1 - возврат узла в нормальное состояние после сервисного режима
- crm node fence node1 - убить (выключить) при помощи STONITH node1
- crm resource cleanup resource1 - удалить счетчики сбоев ресурса resource1 со всех узлов
- crm resource cleanup resource1 node2 - удалить счетчики сбоев ресурса resource1 с узла node2
- crm resource status - просмотр списка ресурсов, запущенных и остановленных
- crm configure delete resource1 - удалить ресурс
- cibadmin –query > config.xml - бекап конфигурации кластера
- cibadmin –replace –xml-file config.xml - восстановление конфигурации из бекапа
- stonith -L - просмотр всех доступных драйверов stonith
- stonith -t type -n - просмотр параметров конкретного драйвера stonith
- crm_mon -1 - смотрим список нод в кластере и их состояние. И текущую главную ноду по результатам голосования (Current DC)
- crm_mon -nr - посмотреть ресурсы, сгруппировав их по узлам, плюс показать не активные ресурсы
- crm_verify -L - проверка конфигурации кластера
- crm configure show - просмотр конфигурации кластера
- crm_simulate -sL - просмотр и симулирование размещения ресурсов по узлам на основе их приоритетов и прочих параметров